


We mention the phrase Mechanical Sympathy quite a lot, in fact it's even Martin's blog title. It's about understanding how the underlying hardware operates and programming in a way that works with that, not against it.
We get a number of comments and questions about the mysterious cache line padding in the RingBuffer, and I referred to it in the last post. Since this lends itself to pretty pictures, it's the next thing I thought I would tackle.
Comp Sci 101
One of the things I love about working at LMAX is all that stuff I learnt at university and in my A Level Computing actually means something. So often as a developer you can get away with not understanding the CPU, data structures or Big O notation - I spent 10 years of my career forgetting all that. But it turns out that if you do know about these things, and you apply that knowledge, you can come up with some very clever, very fast code.
So, a refresher for those of us who studied this at school, and an intro for those who didn't. Beware - this post contains massive over-simplifications.
The CPU is the heart of your machine and the thing that ultimately has to do all the operations, executing your program. Main memory (RAM) is where your data (including the lines of your program) lives. We're going to ignore stuff like hard drives and networks here because the Disruptor is aimed at running as much as possible in memory.
The CPU has several layers of cache between it and main memory, because even accessing main memory is too slow. If you're doing the same operation on a piece of data multiple times, it makes sense to load this into a place very close to the CPU when it's performing the operation (think a loop counter - you don't want to be going off to main memory to fetch this to increment it every time you loop around).
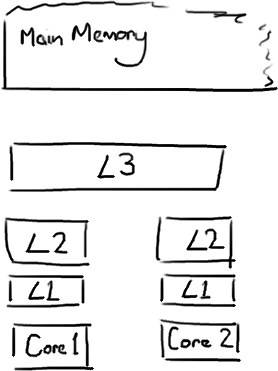
The closer the cache is to the CPU, the faster it is and the smaller it is. L1 cache is small and very fast, and right next to the core that uses it. L2 is bigger and slower, and still only used by a single core. L3 is more common with modern multi-core machines, and is bigger again, slower again, and shared across cores on a single socket. Finally you have main memory, which is shared across all cores and all sockets.
When the CPU is performing an operation, it's first going to look in L1 for the data it needs, then L2, then L3, and finally if it's not in any of the caches the data needs to be fetched all the way from main memory. The further it has to go, the longer the operation will take. So if you're doing something very frequently, you want to make sure that data is in L1 cache.
Martin and Mike's QCon presentation gives some indicative figures for the cost of cache misses:




We get a number of comments and questions about the mysterious cache line padding in the RingBuffer, and I referred to it in the last post. Since this lends itself to pretty pictures, it's the next thing I thought I would tackle.
Comp Sci 101
One of the things I love about working at LMAX is all that stuff I learnt at university and in my A Level Computing actually means something. So often as a developer you can get away with not understanding the CPU, data structures or Big O notation - I spent 10 years of my career forgetting all that. But it turns out that if you do know about these things, and you apply that knowledge, you can come up with some very clever, very fast code.
So, a refresher for those of us who studied this at school, and an intro for those who didn't. Beware - this post contains massive over-simplifications.
The CPU is the heart of your machine and the thing that ultimately has to do all the operations, executing your program. Main memory (RAM) is where your data (including the lines of your program) lives. We're going to ignore stuff like hard drives and networks here because the Disruptor is aimed at running as much as possible in memory.
The CPU has several layers of cache between it and main memory, because even accessing main memory is too slow. If you're doing the same operation on a piece of data multiple times, it makes sense to load this into a place very close to the CPU when it's performing the operation (think a loop counter - you don't want to be going off to main memory to fetch this to increment it every time you loop around).

The closer the cache is to the CPU, the faster it is and the smaller it is. L1 cache is small and very fast, and right next to the core that uses it. L2 is bigger and slower, and still only used by a single core. L3 is more common with modern multi-core machines, and is bigger again, slower again, and shared across cores on a single socket. Finally you have main memory, which is shared across all cores and all sockets.
When the CPU is performing an operation, it's first going to look in L1 for the data it needs, then L2, then L3, and finally if it's not in any of the caches the data needs to be fetched all the way from main memory. The further it has to go, the longer the operation will take. So if you're doing something very frequently, you want to make sure that data is in L1 cache.
Martin and Mike's QCon presentation gives some indicative figures for the cost of cache misses:
| Latency from CPU to... | Approx. number of CPU cycles | Approx. time in nanoseconds |
| Main memory | ~60-80ns | |
| QPI transit (between sockets, not drawn) | ~20ns | |
| L3 cache | ~40-45 cycles, | ~15ns |
| L2 cache | ~10 cycles, | ~3ns |
| L1 cache | ~3-4 cycles, | ~1ns |
| Register | 1 cycle |
If you're aiming for an end-to-end latency of something like 10 milliseconds, an 80 nanosecond trip to main memory to get some missing data is going to take a serious chunk of that.
Cache lines
Now the interesting thing to note is that it's not individual items that get stored in the cache - i.e. it's not a single variable, a single pointer. The cache is made up of cache lines, typically 64 bytes, and it effectively references a location in main memory. A Java
long is 8 bytes, so in a single cache line you could have 8 long variables.
(I'm going to ignore the multiple cache-levels for simplicity)
This is brilliant if you're accessing an array of longs - when one value from the array gets loaded into the cache, you get up to 7 more for free. So you can walk that array very quickly. In fact, you can iterate over any data structure that is allocated to contiguous blocks in memory very quickly. I made a passing reference to this in the very first post about the ring buffer, and it explains why we use an array for it.
So if items in your data structure aren't sat next to each other in memory (linked lists, I'm looking at you) you don't get the advantage of freebie cache loading. You could be getting a cache miss for every item in that data structure.
However, there is a drawback to all this free loading. Imagine your
long isn't part of an array. Imagine it's just a single variable. Let's call it head, for no real reason. Then imagine you have another variable in your class right next to it. Let's arbitrarily call it tail. Now, when you load head into your cache, you get tail for free. 
Which sounds fine. Until you realise that
tail is being written to by your producer, and head is being written to by your consumer. These two variables aren't actually closely associated, and in fact are going to be used by two different threads that might be running on two different cores.
Imagine your consumer updates the value of
head. The cache value is updated, the value in memory is updated, and any other cache lines that contain head are invalidated because other caches will not have the shiny new value. And remember that we deal with the level of the whole line, we can't just mark head as being invalid.
Now if some process running on the other core just wants to read the value of
tail, the whole cache line needs to be re-read from main memory. So a thread which is nothing to do with your consumer is reading a value which is nothing to do with head, and it's slowed down by a cache miss.Of course this is even worse if two separate threads are writing to the two different values. Both cores are going to be invalidating the cache line on the other core and having to re-read it every time the other thread has written to it. You've basically got write-contention between the two threads even though they're writing to two different variables.
This is called false sharing, because every time you access
head you get tail too, and every time you access tail, you get head as well. All this is happening under the covers, and no compiler warning is going to tell you that you just wrote code that's going to be very inefficient for concurrent access.Our solution - magic cache line padding
You'll see that the Disruptor eliminates this problem, at least for architecture that has a cache size of 64 bytes or less, by adding padding to ensure the ring buffer's sequence number is never in a cache line with anything else.
| public long p1, p2, p3, p4, p5, p6, p7; // cache line padding |
| private volatile long cursor = INITIAL_CURSOR_VALUE; |
| public long p8, p9, p10, p11, p12, p13, p14; // cache line padding |
So there's no false sharing, no unintended contention with any other variables, no needless cache misses.
It's worth doing this on your
EDIT: Martin wrote a more technically correct and detailed post about false sharing, and posted performance results too.
Entry classes too - if you have different consumers writing to different fields, you're going to need to make sure there's no false sharing between each of the fields.EDIT: Martin wrote a more technically correct and detailed post about false sharing, and posted performance results too.



























